이미지 리사이즈 성능 개선하기
1. 카페 등록이 너무 느리다.
요즘 카페 서비스는 카페를 트렌디함을 사진으로 보여주는 서비스인데,
사진의 용량이 너무 크기에 화면에 랜더링되는 속도가 너무 느린 문제가 있었다.
그렇기에 이미지를 필요한 크기에 따라 리사이즈 하는 기능을 추가했었다.
그런데 리사이즈 기능을 추가하고 나니, 카페를 등록하는 요청을 처리하는 시간이 너무 오래걸린다.
public List<String> resizeAndUpload(final List<MultipartFile> files, final List<Size> sizes) {
final List<ImageResizer> resizers = files.stream()
.map(this::multipartfileToImageResizer)
.toList();
final long start = System.currentTimeMillis();
resizers.forEach(resizer -> resizer.getResizedImages(sizes).forEach(s3Client::upload));
final long end = System.currentTimeMillis();
System.out.println("수행 시간 : " + (end - start) + "ms");
return resizers.stream()
.map(ImageResizer::getFileName)
.toList();
}리사이즈를 하는 로직 위 아래로 현재 시간을 찍어서 리사이즈에 걸리는 시간이 얼마인지 확인해보았다.
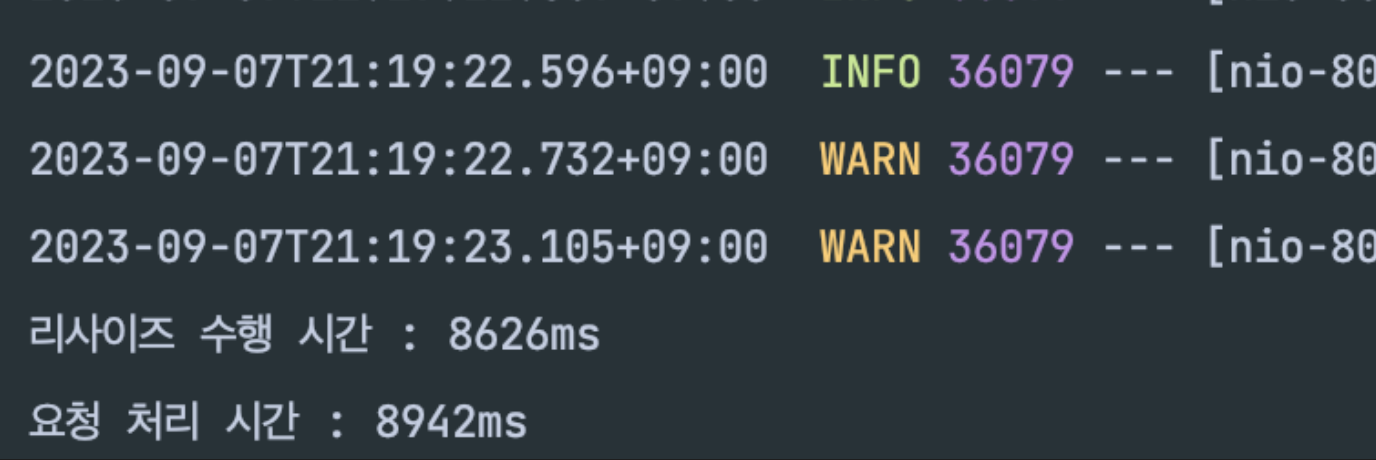
이 요청을 처리하는데 걸리는 시간은 약 8.9초인데,
그 중 리사이즈를 처리하는 시간이 8.6초다.
전체 시간의 약 95% 가량을 리사이즈를 하는데 걸리는 것을 확인할 수 있었다.
리사이즈 기능을 개선 한다면, 전체적인 성능향상을 기대할 수 있다.
2. 병렬 처리로 성능 개선
Stream 을 사용하여 리사이즈를 하고 있는데, Stream 의 특성상 데이터를 순차적으로 처리하고 있다.
이를 병렬적으로 처리한다면, 성능 개선이 이뤄질것이라 생각했다.
2-1. Parallel Stream
Stream을 병렬적으로 처리하는 것은 매우 간단하다.ParallelStream 을 사용하면 된다.
ParallelStream은 자바8 부터 지원된 기능으로
순차적으로 처리되는 일반적인 Stream 과 달리 병렬적으로 Stream을 돌릴 수 있게 지원한다.
@Test
void parallel() {
System.out.println("호출 쓰레드 : " + Thread.currentThread().getName());
IntStream.range(0, 10)
.forEach(num -> {
System.out.println("스트림 쓰레드 : " + Thread.currentThread().getName() + " , Num : " + num);
});
}
위와 같은 테스트코드를 돌려 보면,
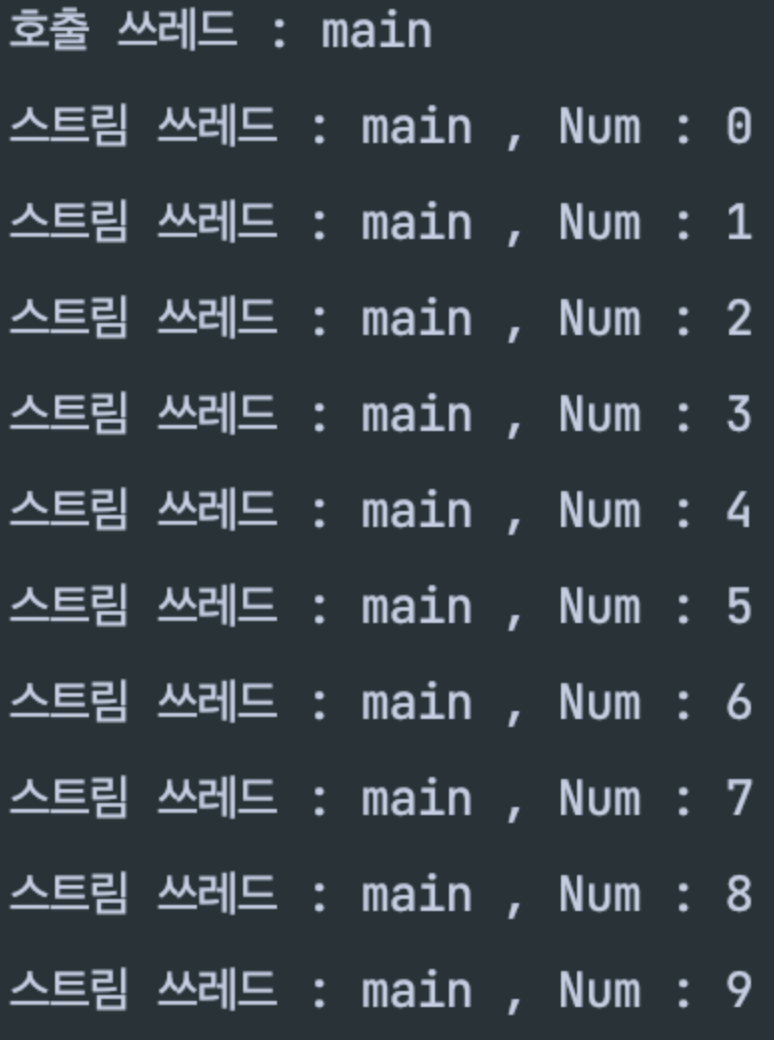
테스트코드가 돌아가는 쓰레드로 0 부터 9까지 순차적으로 데이터를 처리하는 것을 확인할 수 있다.
이번에는 Parallel Stream 으로 변경해서 테스트를 돌려보자.
@Test
void parallel() {
System.out.println("호출 쓰레드 : " + Thread.currentThread().getName());
IntStream.range(0, 10)
.parallel
.forEach(num -> System.out.println("스트림 쓰레드 : " + Thread.currentThread().getName() + " , Num : " + num));
}
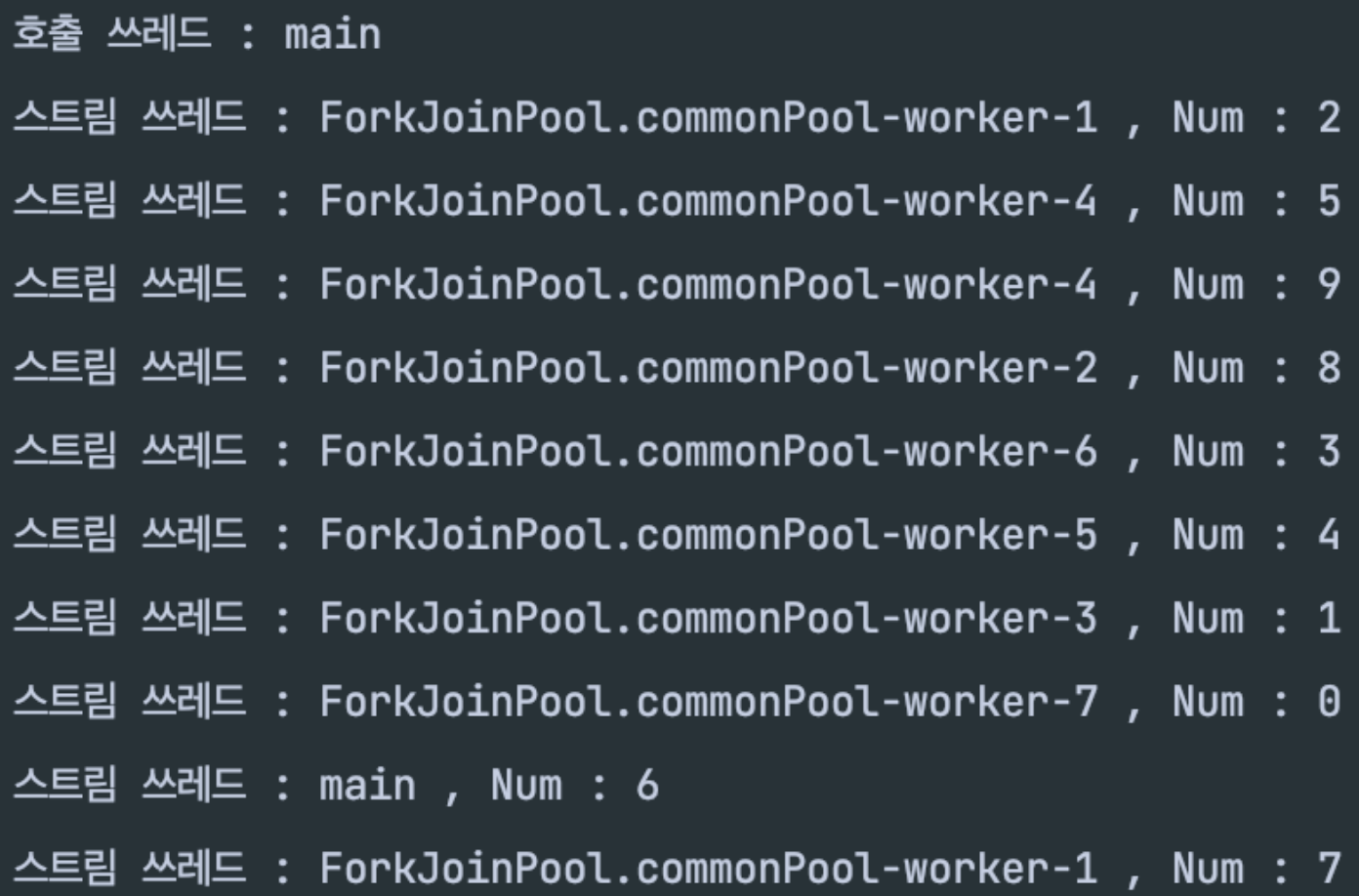
이전과는 달리 숫자가 랜덤하게 뒤섞여 나오며 병렬적으로 처리되는 것을 확인할 수 있다.
또한 ForkJoinPool 이라는 곳에서 가져온 쓰레드를 쓰는걸 확인 할 수 있는데,
ForkJoinPool이 뭘까.
2-2. Fork Join Pool
ForkJoinPool은 Java7에 추가 된 ForkJoin 프레임워크의 핵심 컴포넌트다.
Fork/Join 프레임워크은 병렬 실행을 최대화하기 위해
재귀적으로 문제를 분할하고 결과를 결합하는 알고리즘(분할정복)을 지원한다.
이때 ForkJoinPool은 이런 종류의 작업을 관리하고 실행하는 데 사용되는 특별한 유형의 스레드 풀이다.ForkJoinPool은 작업을 여러 하위 작업으로 분할(fork)하며,
각각의 하위 작업이 완료되면 그 결과들을 다시 합치는(join) 역할을 담당한다.
근데 솔직히 이해가 잘 안된다.
구글링해서 나온 구현예시를 따라해보며 이해를 해보자.
class ForkJoinTest {
@Test
void forkJoin() {
final ForkJoinPool forkJoinPool = new ForkJoinPool();
final Long sum = forkJoinPool.invoke(new SumTask(1, 8));
System.out.println(sum);
}
public static class SumTask extends RecursiveTask<Long> {
private final long from;
private final long to;
public SumTask(final long from, final long to) {
System.out.println("====================================");
System.out.println("FROM : " + from + " , TO : " + to);
this.from = from;
this.to = to;
}
@Override
protected Long compute() {
final long size = to - from + 1;
if (size <= 2) {
long tmp = 0L;
for (long i = from; i <= to; i++) {
tmp += i;
} return tmp;
}
long half = (from + to) / 2;
SumTask left = new SumTask(from, half);
SumTask right
= new SumTask(half + 1, to);
left.fork();
Long compute = right.compute();
Long join = left.join();
return compute + join;
}
}
}Fork/Join 프레임워크는 RecursiveAction 또는 RecursiveTask<V> 를 상속받아 구현해야 한다.~Action 은 반환값이 있는 경우, ~Task 는 반환값이 없는 경우에 사용된다.
1부터 8까지의 값을 모두 더하는 예시이다.
위의 예시는 범위내의 모든 값을 더하고 반환하는 예시이므로, ~Action을 상속받아 구현하였다.
size를 구하고 size가 2이하인 경우에는 더한 값을 반환하고,
그렇지 않은 경우는 다시 분할(Fork) 하여 위의 과정을 반복한다.
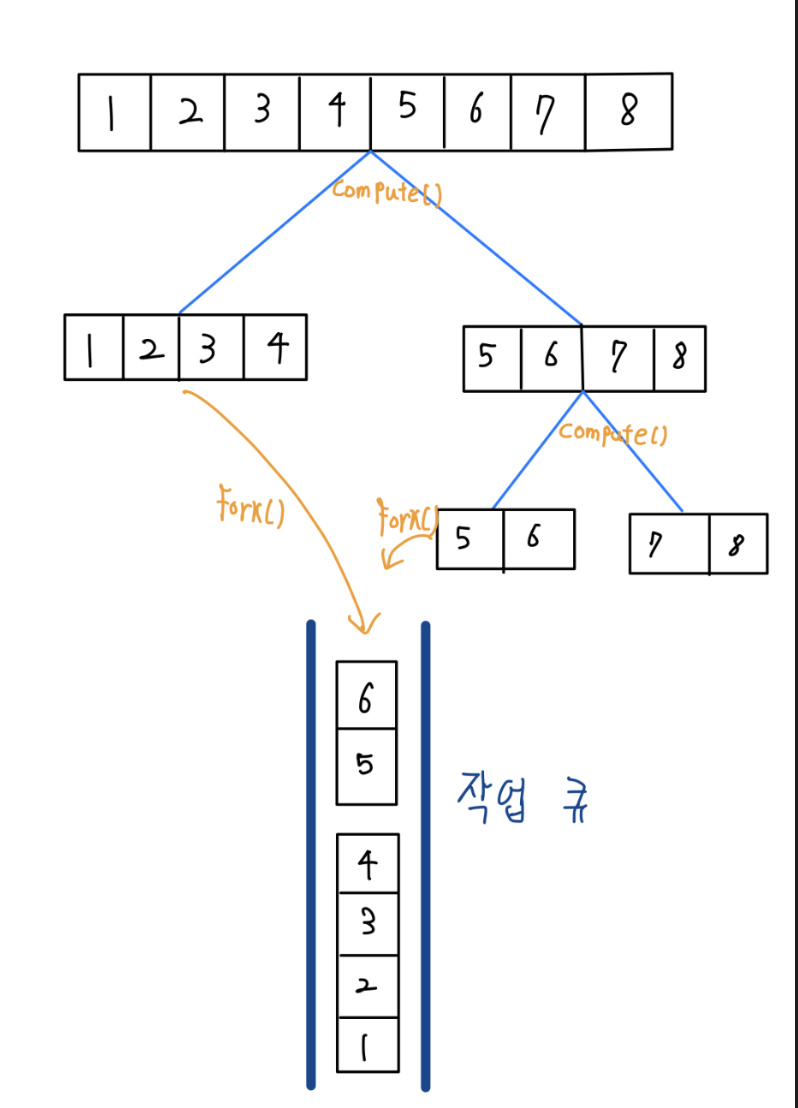
중간 중간 찍어놓은 로그를 확인하면 다음과 같다.
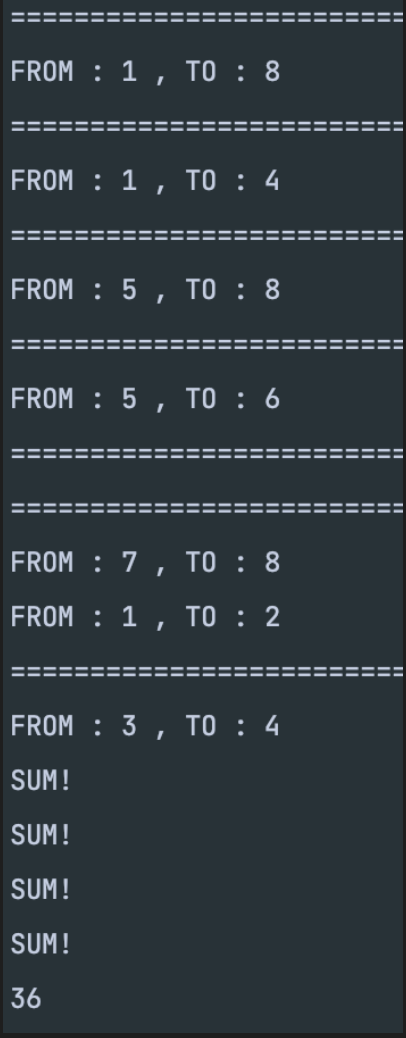
중간에 구분선이 겹쳐서 찍힌것은 분할작업(fork)의 작업이 ForkJoinPool을 이용하여 병렬적으로 처리되기 때문이다.
분할작업이 모두 완료 되면, join 작업을 통해 분할된 작업의 결과를 합쳐준다.
그림으로 보면 아래와 같다.
2-3. ForkJoin vs ExecutorService
여기까지 알아보고 나니, 한가지 궁금점이 생겼다.
ForkJoin이 없던 Java7 이전의 방식(ExecutorService)과는 어떤 차이점이 있을까.
두가지 방식의 차이점은 작업할당 방식에 있다.
ExecutorService 는 쓰레드풀 내에서 공유되는 공용 작업큐가 있고,ForkJoin 은 각각의 쓰레드들이 작업큐(Deque 로 구현되어있다.)를 갖고있다. 그리고 자신(쓰레드)의 일이 끝나면,
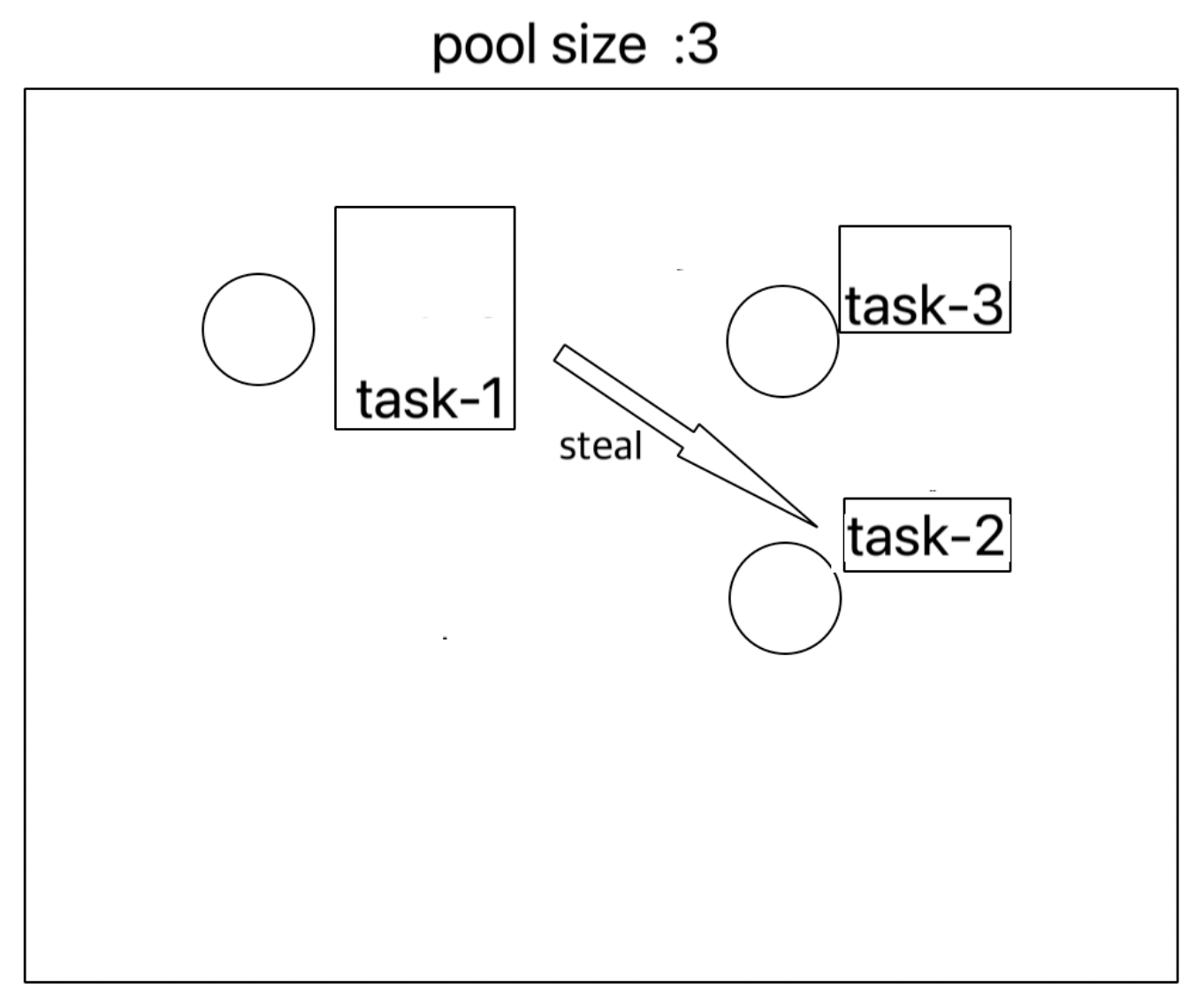
다른 쓰레드의 작업큐에 있는 작업을 훔쳐온다.
이를 Work-Stealing 이라 한다.
이 내용을 처음 접했을 때 이해가 안됐는데, 그림을 그려보니 어느정도 이해가 되었다.

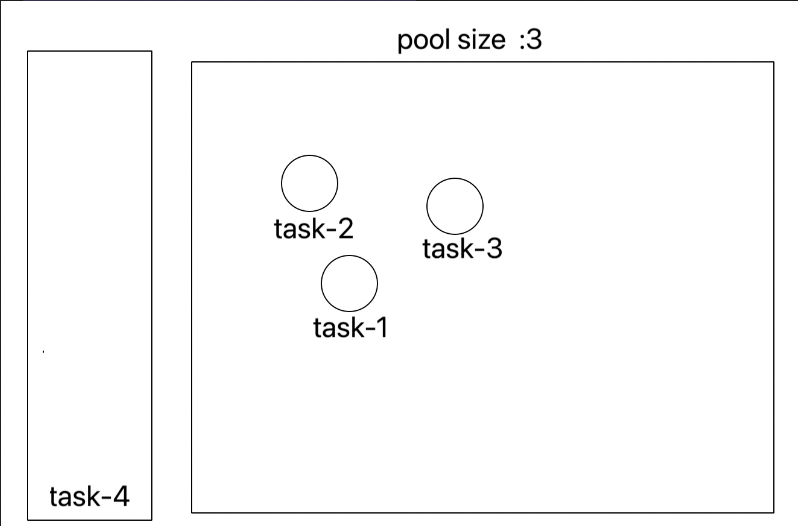
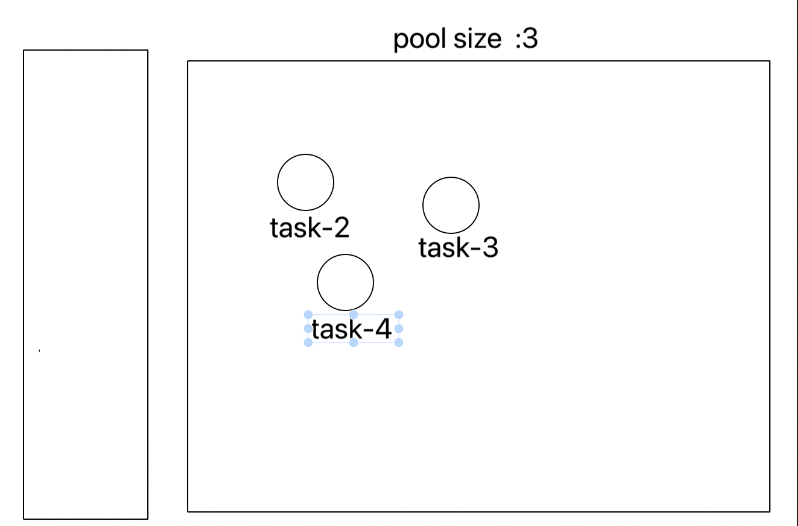
(실제 동작방식을 간략하게 표현 한거)
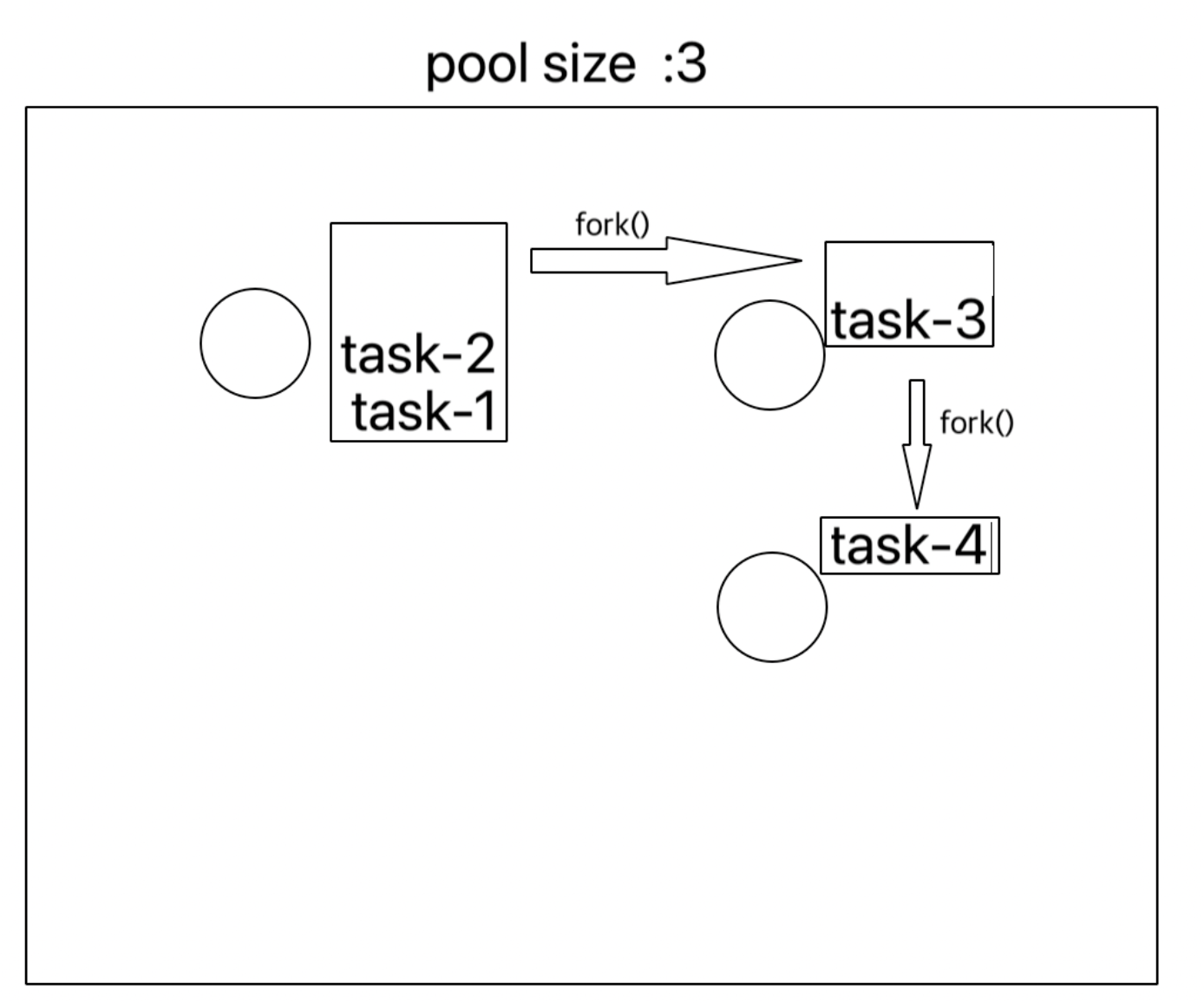
ExecutorService는 공용 작업큐에서 작업을 할당받는다. 이때 쓰레드 풀에 여유 공간이 있다면, 새로운 쓰레드를 생성한다.- 쓰레드는 할당 된 작업을 처리한 뒤, 작업이 남아있다면 해당 작업을 할당 받아 수행한다.(삭제 되지 않고, 재사용)
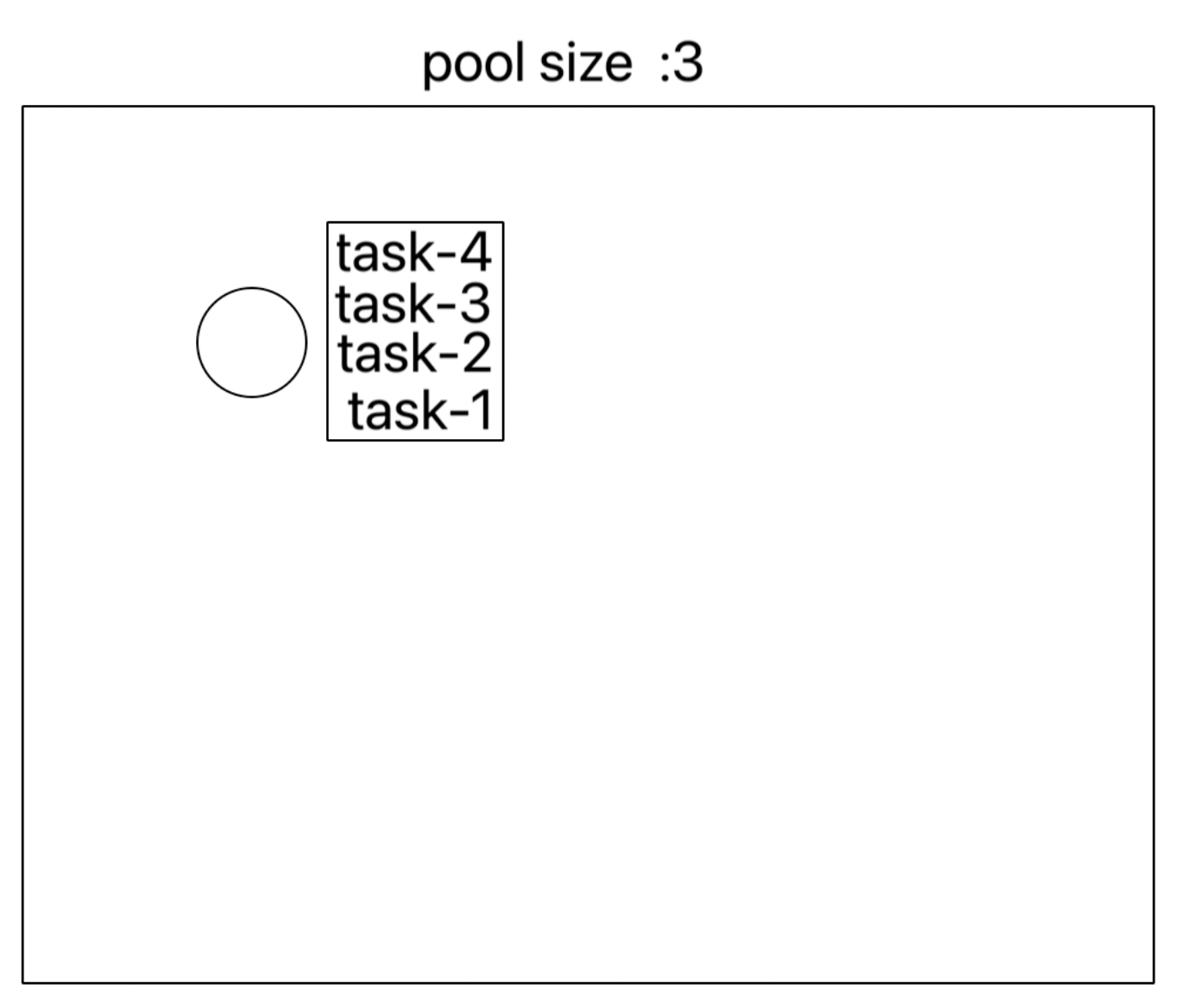
(이 역시 이해를 돕기위해 동작을 간략하게 표현한거)
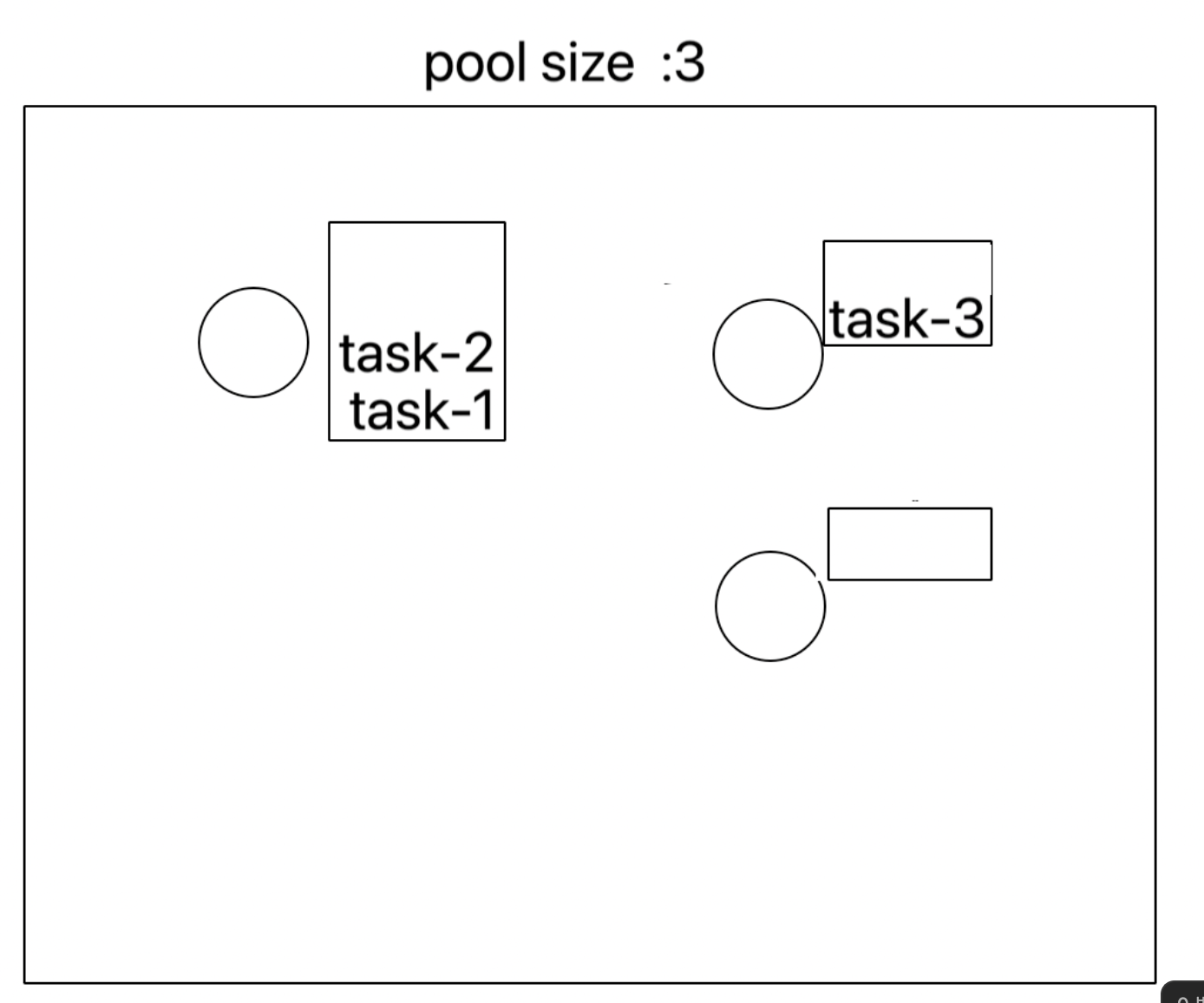
- ForkJoinPool의 쓰레드는 각각의 쓰레드에 작업큐가 존재한다. 하나의 쓰레드에서 모든 작업을 가져온다.
- 작업을 분할(fork) 한다. 이때 스레드풀에 여유공간이 있다면, 새로운 쓰레드를 생성한다.
- 할당 받은 작업을 모두 마친 쓰레드는 다른 쓰레드에 남아있는 작업을 훔쳐와서(steal) 수행한다.
이 정도면, ForkJoin하고 친해진 것 같다.
리팩토링을 해보자.
2-2. 리팩토링
public List<String> resizeAndUpload(final List<MultipartFile> files, final List<Size> sizes) {
final List<ImageResizer> resizers = files.stream()
.map(this::multipartfileToImageResizer)
.toList();
final long start = System.currentTimeMillis();
resizers.parallelStream() // parallelStream()으로 변경.
.forEach(resizer -> resizer.getResizedImages(sizes).forEach(s3Client::upload));
final long end = System.currentTimeMillis();
System.out.println("수행 시간 : " + (end - start) + "ms");
return resizers.stream()
.map(ImageResizer::getFileName)
.toList();
}이해하는데는 오래걸렸지만 리팩토링은 단 한줄만 수정하면 된다.
하핳....
한줄 수정하려고, 오래도 걸렸다.
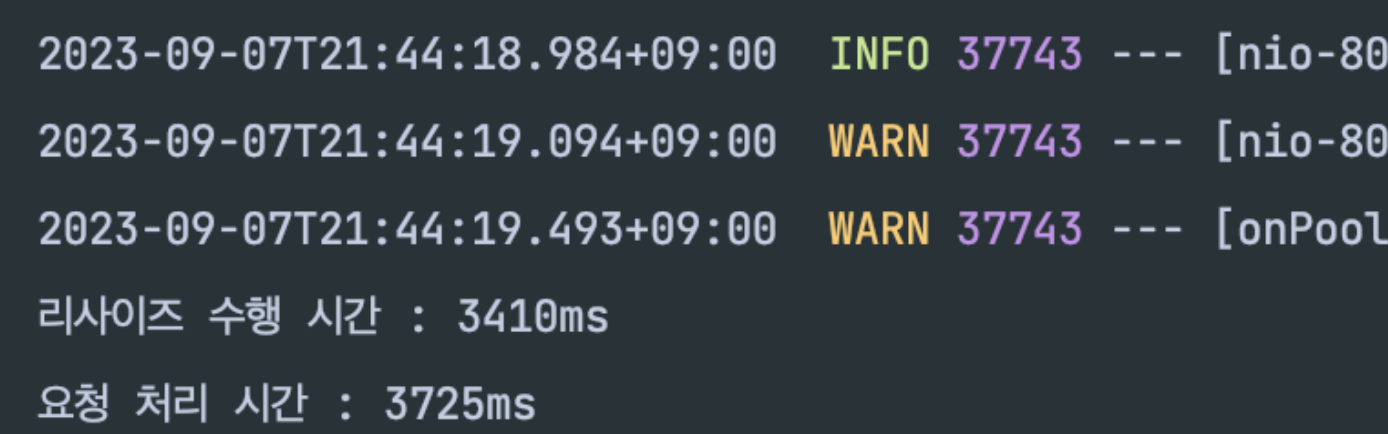
효과는 굉장했다!
8.6초 가량 걸리던 리사이즈 처리가 3.4초로 획기적으로 줄어든 것을 확인 할 수 있었다.
3. 사실 이건.....
사실 위의 결과물들은 전부 내 맥북으로 돌린 결과물이다.
우리의 작고 귀엽고 소중한 EC2는 듀얼코어 따리라 ForkJoinPool의 size가 1로 생성된다.
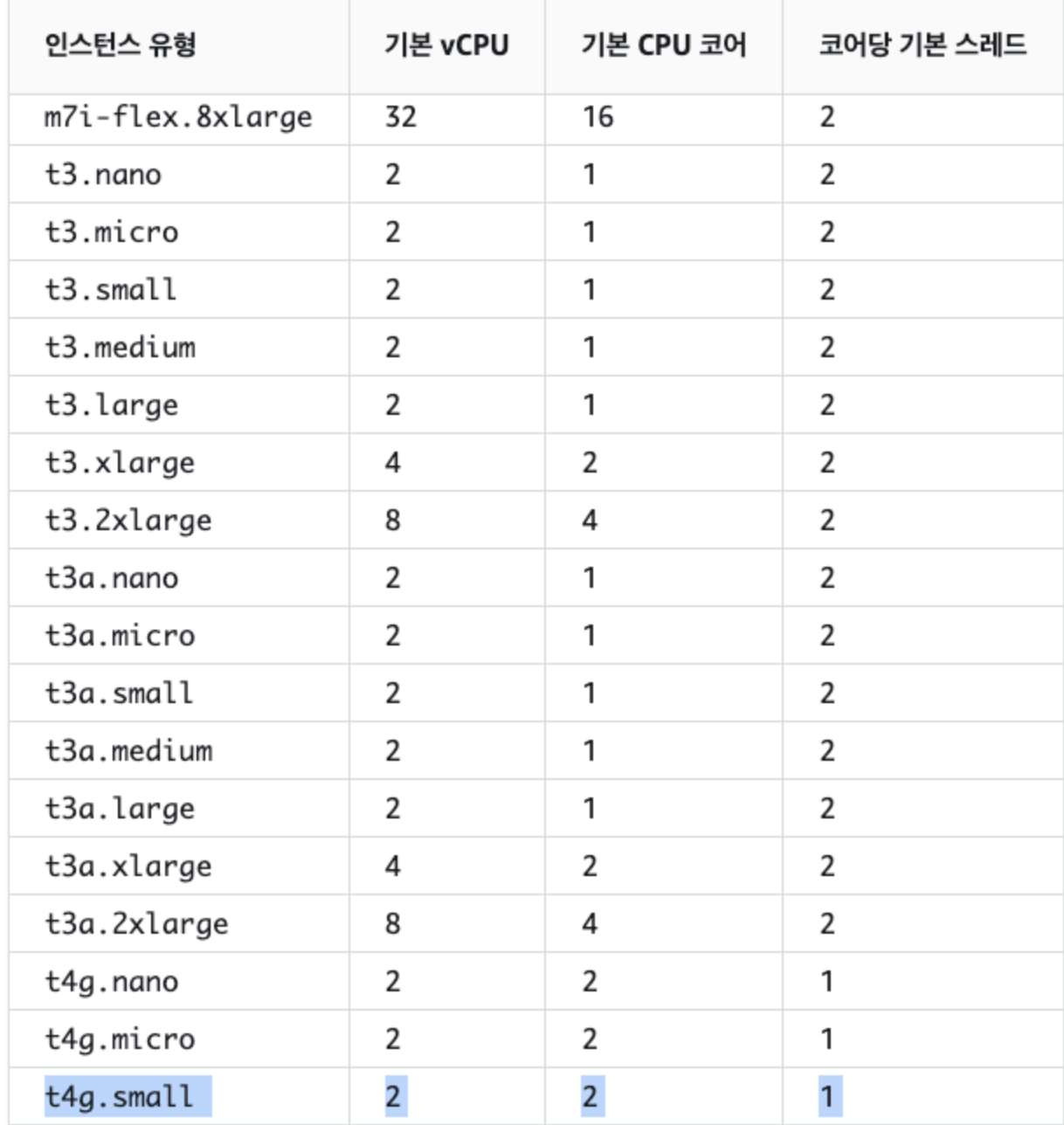
parallelStream을 이용하면 pool size = core -1 개로 생성된다.
아니 그럼 사실상 싱글스레드로 돌아가는 거 아닌가? 싶지만 그건 아니다.
위의 스레드명을 캡쳐한 이미지를 다시 확인해보자.
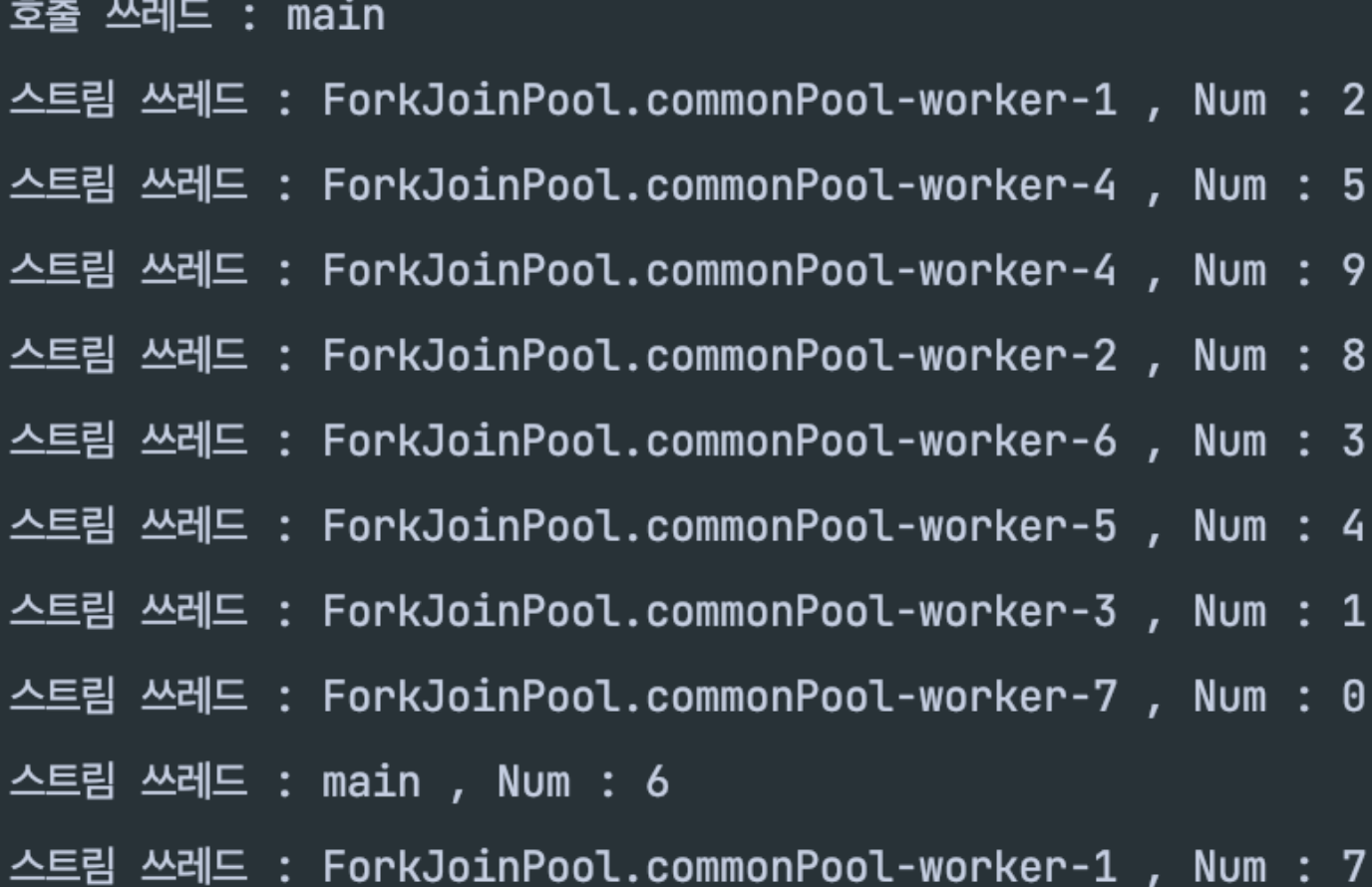
내 로컬환경은 옥타코어 즉, 코어가 8개다 그래서 pool size 가 7로 생성이 되었다.
(쓰레드 넘버링을 확인해보면 최대값이 7인 것을 확인할 수 있다.)
그런데 중간에 호출 쓰레드인 main이 작업에 참여한 것을 확인할 수 있다.
호출쓰레드 + (core 갯수 - 1) 로 병렬작업이 돌아가기에 결국에는 모든 코어의 갯수만큼 스레드가 돌아간다.
우리의 작고 귀여운 EC2에서도 2개의 쓰레드로 열심히 병렬처리를 할것이다.
쓰레드가 두개로 돌아가면 작업속도에 큰 이점이 있을지 궁금해서 직접 풀을 생성해서 돌려봤다.
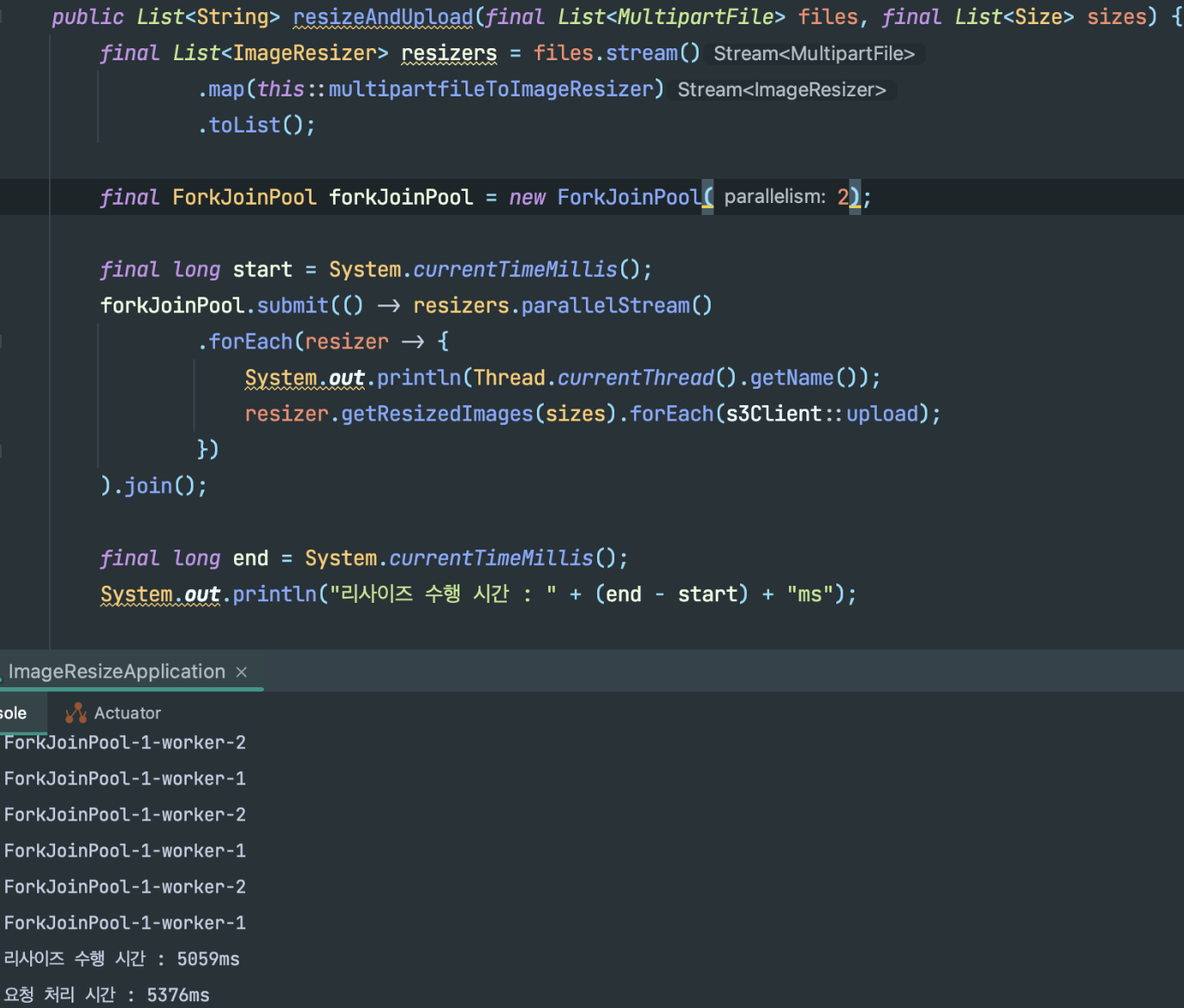
parallelStream으로 매니징 되는 병렬처리만 호출쓰레드가 작업에 참여하기때문에,
풀사이즈를 2로 지정해주었다.
8개의 쓰레드로 돌아갈때 보다는 당연히 효과가 미비하지만,
싱글로 돌아갈때 (8.6초) 에 비하면 많이 개선되었다.
ec2 에서도 비슷한 비율로 성능개선이 이뤄지지 않을까 기대해본다.
3-1. EC2 에서 확인해보기
10장의 사진을 포함하여 카페를 등록해보았다.

기존의 방식대로 라면, 요청을 처리하는데 10.22초가 걸린다.
개선 후

위의 요청과 똑같은 이미지 10장을 포함하여 카페를 등록하니,
10.22초가 걸리던게 5.49초 만 걸린다.
요청에 걸리는 시간이 약 47% 가량 줄어든 것을 확인할 수 있다.
작고 귀여운 듀얼코어가 열심히 일을 하는 듯 하다.
매우 고맙다.